Fairouz Zendaoui, Ecole Nationale Supérieure d'Informatique, Alger, Quantifying and Representing Uncertainty of Historical Information
The digital humanities are a field of research, teaching and engineering at the crossroads of computer science and arts, literature, human and social sciences. Historical disciplines focus on digital tools, especially databases. Current interests and efforts focus on the representation of historical knowledge in order to facilitate the diffusion, sharing and exploitation of collective knowledge. Simplifying and structuring qualitatively complex knowledge, quantifying it in a certain way to make it reusable and easily accessible are all aspects that are not new to historians. Computer science is currently approaching a solution to some of these issues, or at least making it easier to work with historical data.
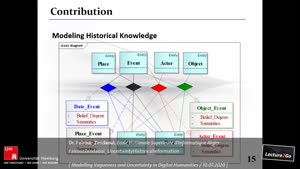
In this context, we proposed a representation model of historical event. The particularity of our model is to represent simultaneously multiple versions of the same event from different sources. It constitutes a field of expertise for new research and investigation problems. Moreover, we extended our model by taking into consideration the quality of imperfection of historical data in terms of uncertainty. To realize this, we based on a multilayer approach in which we distinguished three informational levels: information, source, and belief whose combination allows modeling and modulating historical knowledge. The basic principle of this model is to allow multiple historical sources to represent several versions of a historical event with associated degrees of belief. Furthermore, we differentiated three levels of granularity (attribute, object, relation) to express belief and defined 11 degrees of uncertainty in belief. The proposed model can be the object of various exploitations that fall within the historian’s decision-making support for the plausibility of the history of historical events.
On the other hand, the Web has become the most important information source for most of us and also for historians. Unfortunately, there is no guarantee for the correctness of information on the Web. Moreover, different websites often provide conflicting information on a subject. Several truth discovery methods have been proposed for various scenarios, and they have been successfully applied in diverse application domains. However, none of the previous works has considered the relevance of sources in inferring truths, knowing that it is the main performance metric used by the majority of search engines.
As application of our proposed model, allowing us to represent quantifying beliefs, we implemented it and attempted to answer the question whether the truth is relevant. We conducted an experimental study on real data from the web relative to the location of world heritage sites. We analyzed and compared the results of two different truth discovery methods: Majority vote and relevance-based sources ranking. We have found that the truth is not always held by the most relevant sources on the web. In some cases, the truth is given by the majority vote of the crowd. In addition, we have proposed a method of presenting the results of truth discovery with gradual degrees of belief. A method that allows to configure and target the desired level of trust.
https://www.inf.uni-hamburg.de/inst/dmp/hercore/publications/vaguenessuncertainty2020.html
Digital Humanities (DH) aims not only to archive and make available materials (in particular historical artefacts) but also to introduce a better scientific reflexion into humanities by propagating computational methods. However more than ten years of consequent employment of computer-aided research did not lead to a hermeneutic-adequate digital modelling of historical objects. The main crux remains in most DH-attempts the storage of objects in database architectures designed for natural science application, the annotation with very general metadata, the mark-up with shallow linguistic information no after the language or the purpose of the document and the quantitative analysis. Not only images and texts become artificially precise, but the mutual illumination of texts and other media loses its traditional hermeneutic power.
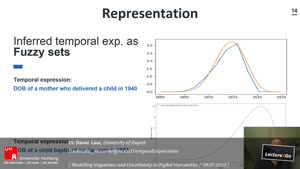
Vagueness is one of the most important, most significant but most difficult features of historical objects, especially texts and images. Whereas ambiguity – several distinct but clear meanings- and uncertainty – conceptually clear but unknown or forgotten data - are relatively well describable phenomena, vagueness is undefined by semantics or pragmatics.
This workshop aims at bringing together for the first time experts in representation of vagueness and uncertainty and scholars from DH who went beyond state-of the art in their research and tried to apply existent theories like fuzzy logic in their work.